是一種機器學習框架,由兩個神經網路組成,目標是生成具有與訓練集相似特徵新數據
生成器(Generator):負責創建新數據樣本。接受隨機輸入並生成輸出,希望判別器會認為它是真實的
判別器(Discriminator):負責區分真實數據樣本和生成器生成的假數據樣本。接受輸入並輸出輸入為真實的概率
對抗訓練:兩個網路以對抗方式一起訓練。生成器嘗試提高生成假數據的能力,判別器無法將其與真實數據區分開來,而判別器則嘗試提高區分真實和假數據的能力
收斂: 隨著兩個網路相互訓練,它們在各自的任務中變得越來越好。最終,生成器能夠產生非常逼真的假數據,而判別器變得非常擅長區分真實和假數據
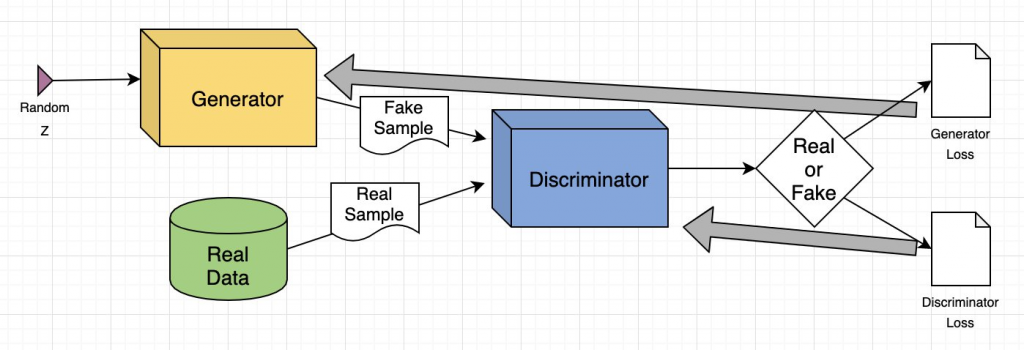
圖片來源:(https://aws.amazon.com/tw/what-is/gan/)
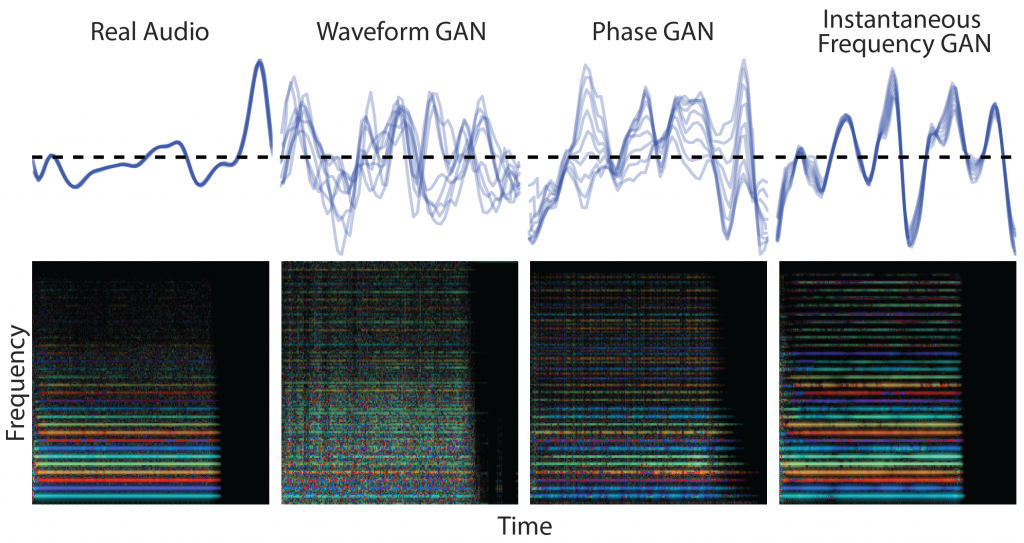
圖像生成GAN可用生成逼真的人物、物體、場景圖像

圖片來源:(https://machinelearningmastery.com/impressive-applications-of-generative-adversarial-networks/)
視頻生成GAN可用生成逼真視頻

圖片來源:(https://machinelearningmastery.com/impressive-applications-of-generative-adversarial-networks/)
文本生成GAN可用生成逼真文本,例如:新聞文章或創意寫作
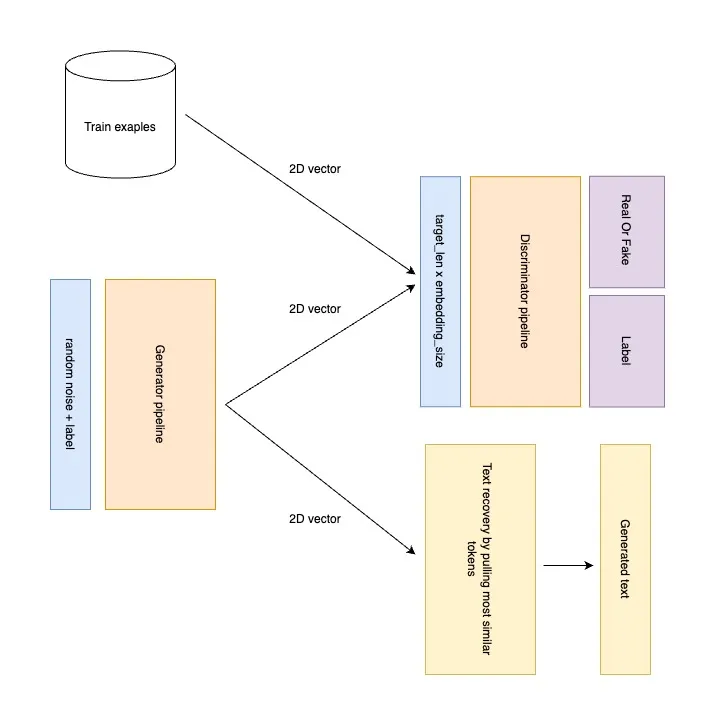
圖片來源:(https://medium.com/@salaxieb.ildar/text-gan-on-embeddings-debb9a006fff)
音樂生成GAN可用生成逼真音樂,例如:新歌曲或不同樂器作品
圖片來源:(https://magenta.tensorflow.org/gansynth)
生成與真實數據無法區分的數據:能夠生成非常逼真的數據,成為各種應用程序的強大工具無需標記數據:不需要標記數據進行訓練,成為難以或昂貴地獲取標記數據的任務的良好選擇可能難以訓練:可能難以訓練,有時它們可能會陷入僅生成有限種類數據的模式可能對超參數敏感:對超參數的值很敏感,可能使它們難以有效使用生成器損失生成器損失函數,記為 G_loss,捕獲生成器欺騙判別器相信生成數據為真實數據能力。通常使用二進制交叉熵損失函數來表示,函數衡量判別器對真實和生成數據輸出的差異。
G_loss = - E_x[log(D(x))] - E_z[log(1 - D(G(z)))]
E_x 對從真實數據分布 p_data(x) 中抽取的真實數據樣本 x 期望
E_z 對從先驗分布 p_z(z) 中抽取的隨機噪聲向量 z 期望
D(x) 表示判別器分配給輸入 x 為真實概率
D(G(z)) 表示判別器分配給生成數據樣本 G(z) 為真實概率
判別器損失判別器損失函數,記為 D_loss,旨在提高其準確區分真實數據和生成數據的能力。通常使用二進制交叉熵損失函數來表示,具有針對真實和生成數據的單獨項。
D_loss = - E_x[log(D(x))] - E_z[log(1 - D(G(z)))]
使用各自損失函數迭代更新生成器和判別器。目標是驅動生成器生成越來越逼真的數據欺騙判別器,同時提高判別器區分真實和生成數據的能力
更新生成器更新判別器各自損失函數驅動更新生成器和判別器這種迭代過程導致對這兩種模型持續改進。生成器變得越來越擅長生成逼真的數據,而判別器則提高區分真實和生成數據的能力
GAN基本公式,包括生成器和判別器的損失函數和更新規則,為訓練這些強大的機器學習模型奠定了基礎。通過這些公式的相互作用,生成器和判別器進行了一場對抗的舞蹈,推動彼此提高各自的能力。這種動態的相互作用最終導致生成越來越逼真和令人信服的數據,總體而言,GAN 是一種功能強大的工具,具有廣泛的應用。但是,它們可能難以訓練和有效使用
資料來源:[機器學習] GAN 筆記